基础概念
仓库(Repository) :可以简单理解为一个项目的文件夹,它里面包含了项目的所有文件以及这些文件的修改历史记录等信息。例如你开发一个网站项目,整个网站相关的代码、配置文件等所在的这个 “管理空间” 就是仓库,本地仓库存在于你的电脑上,而远程仓库一般放在类似 GitHub、GitLab 等代码托管平台上。
提交(Commit) :是将你对文件做出的修改记录下来的一个操作,相当于给项目在某个时间点拍了一张 “快照”,记录下当时文件的状态以及你所做的变更描述(通过提交信息体现)。比如你修改了网站项目中某个页面的样式代码,把修改后的代码状态通过提交保存下来,方便后续追溯和管理。
分支(Branch) :分支就是在原有代码基础上开辟出来的一条独立的开发线。例如主分支(通常叫 master 或者 main 分支)一般存放稳定可发布的代码,而当你要开发新功能时,可以创建一个新的分支(如 feature - 登录功能分支),在这个分支上进行功能开发,不会影响主分支的代码,等功能开发完成并测试通过后再合并到主分支上。
远程仓库:指存储在云端的仓库,所有人以该仓库上的代码进行协作
本地仓库:存在于你的电脑上,你可以在它上面进行各种操作,包括提交、查看提交记录、查看状态、查看分支、查看远程仓库等。可以理解是远程仓库的一个副本。
本地仓库与远程仓库:通过push和pull等命令进行同步。Push:将本地仓库中的代码推送到远程仓库,Pull:将远程仓库中的代码拉到本地仓库。
分支策略(团队协作)
Git flow
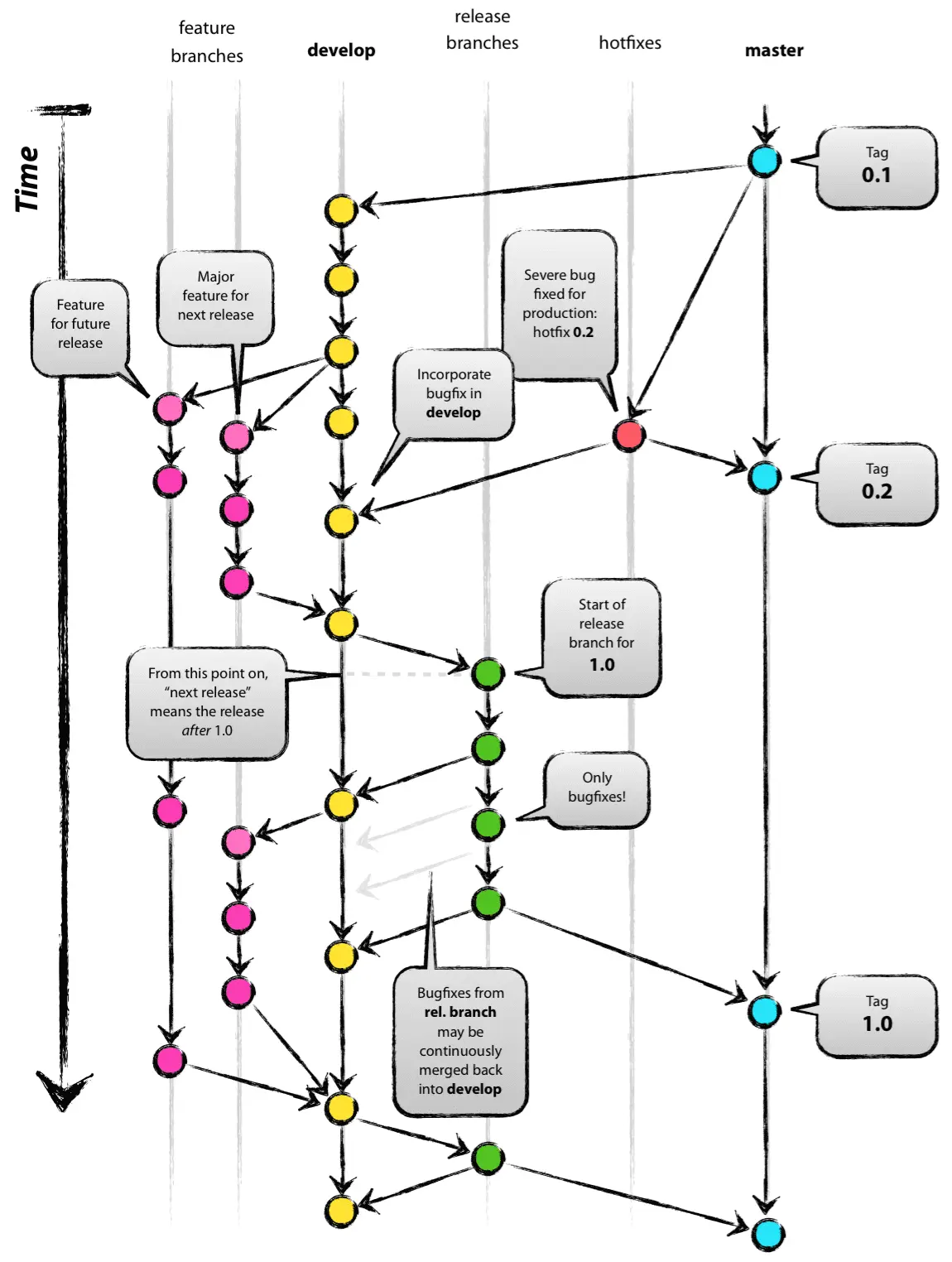
长期分支:master、develop
临时分支:除master、develop外所有分支,一旦完成开发,它们就会被合并进develop或master,然后被删除。
Git flow的优点是清晰可控,缺点是相对复杂,需要同时维护两个长期分支。大多数工具都将master当作默认分支,可是开发是在develop分支进行的,这导致经常要切换分支,非常烦人。
更大问题在于,这个模式是基于”版本发布”的,目标是一段时间以后产出一个新版本。但是,很多网站项目是”持续发布”,代码一有变动,就部署一次。这时,master分支和develop分支的差别不大,没必要维护两个长期分支。
GitHub Flow
Github flow 是Git flow的简化版,专门配合”持续发布”。它是 Github.com 使用的工作流程。
它只有一个长期分支,就是master,因此用起来非常简单。
第一步:根据需求,从master拉出新分支,不区分功能分支或补丁分支。
第二步:新分支开发完成后,或者需要讨论的时候,就向master发起一个pull request(简称PR)。
第三步:Pull Request既是一个通知,让别人注意到你的请求,又是一种对话机制,大家一起评审和讨论你的代码。对话过程中,你还可以不断提交代码。
第四步:你的Pull Request被接受,合并进master,重新部署后,原来你拉出来的那个分支就被删除。(先部署再合并也可。)
Github flow 的最大优点就是简单,对于”持续发布”的产品,可以说是最合适的流程。
问题在于它的假设:master分支的更新与产品的发布是一致的。也就是说,master分支的最新代码,默认就是当前的线上代码。
可是,有些时候并非如此,代码合并进入master分支,并不代表它就能立刻发布。比如,苹果商店的APP提交审核以后,等一段时间才能上架。这时,如果还有新的代码提交,master分支就会与刚发布的版本不一致。另一个例子是,有些公司有发布窗口,只有指定时间才能发布,这也会导致线上版本落后于master分支。
上面这种情况,只有master一个主分支就不够用了。通常,你不得不在master分支以外,另外新建一个production分支跟踪线上版本。
GitLab Flow
Gitlab flow 是 Git flow 与 Github flow 的综合。它吸取了两者的优点,既有适应不同开发环境的弹性,又有单一主分支的简单和便利。它是 Gitlab.com 推荐的做法。
Gitlab flow 的最大原则叫做”上游优先”(upsteam first),即只存在一个主分支master,它是所有其他分支的”上游”。只有上游分支采纳的代码变化,才能应用到其他分支。
Gitlab flow分为两种:持续发布和版本发布
持续发布
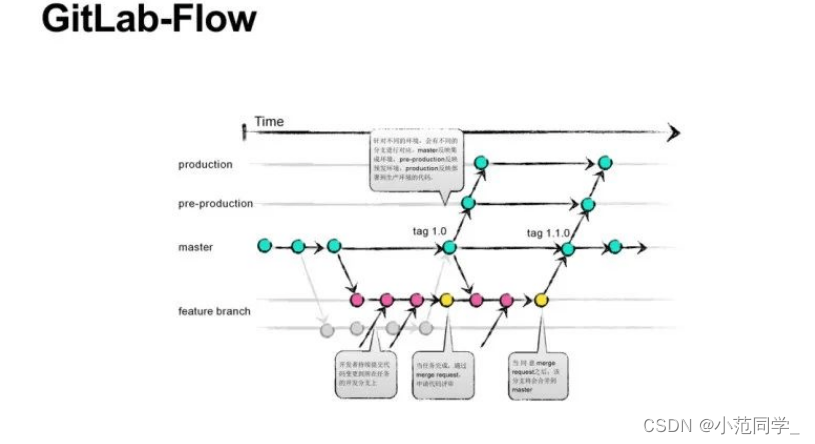
对于”持续发布”的项目,它建议在master分支以外,再建立不同的环境分支。比如,”开发环境”的分支是master,”预发环境”的分支是pre-production,”生产环境”的分支是production。
开发分支是预发分支的”上游”,预发分支又是生产分支的”上游”。代码的变化,必须由”上游”向”下游”发展。比如,生产环境出现了bug,这时就要新建一个功能分支,先把它合并到master,确认没有问题,再cherry-pick到pre-production,这一步也没有问题,才进入production。
只有紧急情况,才允许跳过上游,直接合并到下游分支。
版本发布

对于”版本发布”的项目,建议的做法是每一个稳定版本,都要从master分支拉出一个分支,比如2-3-stable、2-4-stable等等。
以后,只有修补bug,才允许将代码合并到这些分支,并且此时要更新小版本号。
命令
全局配置
1 | # 设置个人信息 |
快捷键及通用指令
快捷键
在部分git命令返回结果中,还可以使用快捷键:
| 按键 | 功能 |
|---|---|
| PgUP | 上一页 |
| PgDn | 下一页 |
| Home | 开始页 |
| End | 结束页 |
| H | 帮助 |
| Q | 退出 |
HEAD
| 方式1 | 方式2 | 说明 |
|---|---|---|
| HEAD | HEAD~0 | 当前版本 |
| HEAD^ | HEAD~1 | 上一个版本 |
| HEAD^^ | HEAD~2 | 上上一个版本 |
| HEAD^^^ | HEAD~3 | 上上上一个版本 |
| 以此类推 | 以此类推 | … |
创建 init/clone
1 |
|
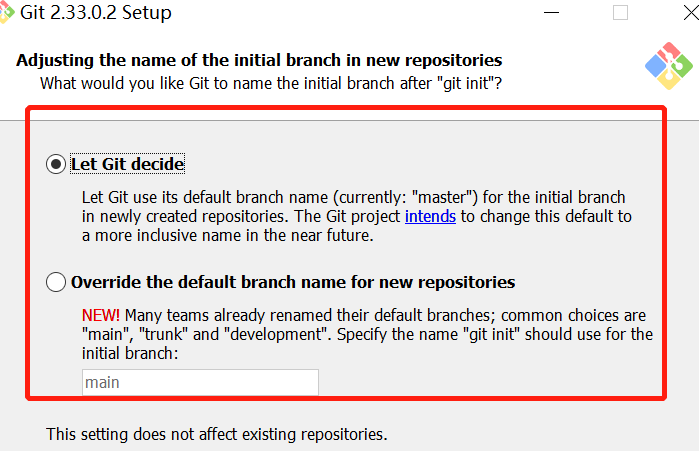
git init默认创建的分支名称可更改,从git for windows软件安装过程也可以看出:
查看状态 status/log/show
工作区与缓存区的状态 status
1 | # 显示工作目录和暂存区的状态,查看哪些修改被暂存,哪些没有 |
状态码:
| 状态码 | 描述 |
|---|---|
| ’ ’ | unmodified |
| M | modified |
| A | added |
| D | deleted |
| R | renamed |
| C | copied |
| U | updated but unmerged |
| ?? | untracked |
| !! | ignored |
已提交的记录 log/show
log
1 | 显示完整项目历史 |
git show
1 | # 查看最后一次的commit记录 |
.gitignore
- 注释:
# - 忽略文件和目录:
folderName。忽略folderName同名文件和目录,包括多级目录 - 忽略文件:
folderName、!folderName/。仅忽略folderName文件,而不忽略folderName目录 - 忽略目录:
folderName/。包括多级目录 - 通配符:
*。匹配多个字符 - 通配符:
?。匹配除/以外的任意一个字符 - 方括号:
[]。匹配多个列表中的任意一个字符,如*.[io],.i和.o文件都会被忽略 - 方括号-短划线:
[X-X]。所有在这两个字符范围内的都可以匹配,如[0-9]表示匹配所有0到9的数字 - 反向操作:
! - 多级目录:
** - 防止递归:以
/开头
注意:
- git跟踪文件,而不是目录
- 在
.gitignore文件中,每行表示一种模式 - 如果本地仓库文件已被跟踪,那么即使在
.gitignore中设置了忽略,也不起作用
添加 add
1 | # 将本地所有untrack文件加入暂存区,并根据.gitignore过滤 |
暂存 stash
stash:将本地没提交的内容(已加入版本控制)进行缓存并从当前分支移除,缓存的数据结构为堆栈,先进后出.
1 |
|
查看不同 diff
工作区的比较 diff
1 | # 比较工作区(git add前)和暂存区(git add后)所有文件差异 |
暂存区的比较 diff –cached
1 | # 比较暂存区和上一次提交所有文件差异 |
不同版本库的比较 diff
1 | # 查看两个(提交)版本之间的差异 |
重置 reset
1 | # git reset 命令用于回退版本,可以指定退回某一次提交的版本。 |
清除 Untracked File
1 | # 删除单个文件 |
提交 commit
1 | $ git commit -m "第一次提交" |
指定远程仓库 remote
1 | # 指定仓库地址 |
推送 push
1 | # -u: 指定远程仓库(upstream)和远程分支,使用该命令后,以后使用git push 或 git pull 都是默认对应origin下的master分支 |
拉取 pull
1 |
|
分支管理 branch
1 | # 查看所有本地和远程分支 |
切换分支 checkout
1 |
|
合并分支/提交 merge/rebase
merge
1 | # git-merge命令是用于从指定的commit(s)合并到当前分支的操作 |
有以下两种用途:
- 用于git-pull中,来整合另一代码仓库中的变化(即:git pull = git fetch + git merge)
- 用于从一个分支到另一个分支的合并
注意:当合并开始时如果存在未commit的文件,则不能重建合并前状态。因此非常不鼓励在使用git-merge时存在未commit的文件,建议使用git-stash命令将这些未commit文件暂存起来,并在解决冲突以后使用git stash pop把这些未commit文件还原出来
参数
| 参数 | 作用 |
|---|---|
| –commit | 使得合并后产生一个合并结果的commit节点。该参数可以覆盖–no-commit |
| –no-commit | 使得合并后,为了防止合并失败并不自动提交,能够给使用者一个机会在提交前审视和修改合并结果 |
| –edit -e |
用于在成功合并、提交前调用编辑器来进一步编辑自动生成的合并信息。因此使用者能够进一步解释和判断合并的结果 |
| –no-edit | 用于接受自动合并的信息(通常情况下并不鼓励这样做) |
| –ff | 指fast-forward命令。当使用fast-forward模式进行合并时,将不会创造一个新的commit节点。默认情况下,git-merge采用fast-forward模式 |
| –no-ff | 即使可以使用fast-forward模式,也要创建一个新的合并节点。这是当git merge在合并一个tag时的默认行为 |
| –ff-only | 除非当前HEAD节点已经up-to-date(更新指向到最新节点)或者能够使用fast-forward模式进行合并,否则的话将拒绝合并,并返回一个失败状态 |
| –log[=<n>] | 将在合并提交时,除了含有分支名以外,还将含有最多n个被合并commit节点的日志信息 |
| –no-log | 不会列出该信息 |
| –stat | 将会在合并结果的末端显示文件差异的状态。文件差异的状态也可以在git配置文件中的merge.stat配置 |
| –no-stat -n |
将不会显示该信息 |
| –squash | 当一个合并发生时,从当前分支和对方分支的共同祖先节点之后的对方分支节点,一直到对方分支的顶部节点将会压缩在一起,使用者可以经过审视后进行提交,产生一个新的节点(与–no-ff冲突) |
| –no-squash | 相反 |
| –strategy=<strategy> -s <strategy> |
用于指定合并的策略。默认情况如果没有指定该参数,git将按照下列情况采用默认的合并策略: 1.合并节点只含有单个父节点时(如采用fast-forward模式时),采用recursive策略(下文介绍) 2.合并节点含有多个父节点时(如采用no-fast-forward模式时),采用octopus策略(下文介绍) |
| –strategy-option=<option> -X <option> |
在-s <strategy>时指定该策略的具体参数(下文介绍) |
| –verify-signatures –no-verify-signatures |
用于验证被合并的节点是否带有GPG签名,并在合并中忽略那些不带有GPG签名验证的节点 |
| –quiet -q |
静默操作,不显示合并进度信息 |
| –verbose -v |
显示详细的合并结果信息 |
| –progress –no-progress |
切换是否显示合并的进度信息。如果二者都没有指定,那么在标准错误发生时,将在连接的终端显示信息。请注意,并不是所有的合并策略都支持进度报告 |
| –gpg-sign[=<keyid>] -S[<keyid>] |
GPG签名 |
| -m <msg> | 设置用于创建合并节点时的提交信息。如果指定了–log参数,那么commit节点的短日志将会附加在提交信息里 |
| –[no-]rerere-autoupdate | rerere即reuse recorded resolution,重复使用已经记录的解决方案。它允许你让 Git 记住解决一个块冲突的方法,这样在下一次看到相同冲突时,Git 可以为你自动地解决它 |
| –abort | 抛弃当前合并冲突的处理过程并尝试重建合并前的状态(未commit的文件可能不会正确回到合并前状态) |
关于合并的其他概念
合并前的检测
在合并外部分支时,你应当保持自己分支的整洁,否则的话当存在合并冲突时将会带来很多麻烦。
为了避免在合并提交时记录不相关的文件,如果有任何在index所指向的HEAD节点中登记的未提交文件,git-pull和git-merge命令将会停止。
fast-forward合并
通常情况下分支合并都会产生一个合并节点,但是在某些特殊情况下例外。例如调用git pull命令更新远端代码时,如果本地的分支没有任何的提交,那么没有必要产生一个合并节点。这种情况下将不会产生一个合并节点,HEAD直接指向更新后的顶端代码,这种合并的策略就是fast-forward合并。
合并细节
除了上文所提到的fast-forward合并模式以外,被合并的分支将会通过一个合并节点和当前分支绑在一起,该合并节点同时拥有合并前的当前分支顶部节点和对方分支顶部节点,共同作为父节点。
一个合并了的版本将会使所有相关分支的变化一致,包括提交节点,HEAD节点和index指针以及节点树都会被更新。只要这些节点中的文件没有重叠的地方,那么这些文件的变化都会在节点树中改动并更新保存。
如果无法明显地合并这些变化,将会发生以下的情况:
- HEAD指针所指向的节点保持不变
MERGE_HEAD指针被置于其他分支的顶部- 已经合并干净的路径在index文件和节点树中同时更新
- 对于冲突路径,index文件记录了三个版本:版本1记录了二者共同的祖先节点,版本2记录了当前分支的顶部,即HEAD,版本3记录了
MERGE_HEAD。节点树中的文件包含了合并程序运行后的结果。例如三路合并算法会产生冲突 - 其他方面没有任何变化。特别地,你之前进行的本地修改将继续保持原样。如果你尝试了一个导致非常复杂冲突的合并,并想重新开始,那么可以使用
git merge --abort
三路合并算法
三路合并算法是用于解决冲突的一种方式,当产生冲突时,三路合并算法会获取三个节点:本地冲突的B节点,对方分支的C节点,B,C节点的共同最近祖先节点A。三路合并算法会根据这三个节点进行合并。具体过程是,B,C节点和A节点进行比较,如果B,C节点的某个文件和A节点中的相同,那么不产生冲突;如果B或C只有一个和A节点相比发生变化,那么该文件将会采用该变化了的版本;如果B和C和A相比都发生了变化,且变化不相同,那么则需要手动去合并;如果B,C都发生了变化,且变化相同,那么并不产生冲突,会自动采用该变化的版本。最终合并后会产生D节点,D节点有两个父节点,分别为B和C。
合并tag
当合并一个tag时,Git总是创建一个合并的提交,即使这时能够使用fast-forward模式。该提交信息的模板预设为该tag的信息。额外地,如果该tag被签名,那么签名的检测信息将会附加在提交信息模板中。
冲突是如何表示的
当产生合并冲突时,该部分会以<<<<<<<, ``=======和>>>>>>>表示。在=======之前的部分是当前分支这边的情况,在=======`之后的部分是对方分支的情况。
如何解决冲突
在看到冲突以后,你可以选择以下两种方式:
- 决定不合并。这时,唯一要做的就是重置index到HEAD节点。
git merge --abort用于这种情况。 - 解决冲突。Git会标记冲突的地方,解决完冲突的地方后使用
git add加入到index中,然后使用git commit产生合并节点。
可以用以下工具来解决冲突:
- 使用合并工具。
git mergetool将会调用一个可视化的合并工具来处理冲突合并。 - 查看差异。
git diff将会显示三路差异(三路合并中所采用的三路比较算法)。 - 查看每个分支的差异。
git log --merge -p \<path\>将会显示HEAD版本和MERGE_HEAD版本的差异。 - 查看合并前的版本。
git show :1:文件名显示共同祖先的版本,git show :2:文件名显示当前分支的HEAD版本,git show :3:文件名显示对方分支的MERGE_HEAD版本。
合并策略
resolve
仅仅使用三路合并算法合并两个分支的顶部节点(例如当前分支和你拉取下来的另一个分支)。这种合并策略遵循三路合并算法,由两个分支的HEAD节点以及共同子节点进行三路合并。
当然,真正会困扰我们的其实是交叉合并(criss-cross merge)这种情况。所谓的交叉合并,是指共同祖先节点有多个的情况,例如在两个分支合并时,很有可能出现共同祖先节点有两个的情况发生,这时候无法按照三路合并算法进行合并(因为共同祖先节点不唯一)。resolve策略在解决交叉合并问题时是这样处理的,这里参考《Version Control with Git》:
In criss-cross merge situations, where there is more than one possible merge basis, the resolve strategy works like this: pick one of the possible merge bases, and hope for the best. This is actually not as bad as it sounds. It often turns out that the users have been working on different parts of the code. In that case, Git detects that it’s remerging some changes that are already in place and skips the duplicate changes, avoiding the conflict. Or, if these are slight changes that do cause conflict, at least the conflict should be easy for the developer to handle
这里简单翻译一下:在交叉合并的情况时有一个以上的合并基准点(共同祖先节点),resolve策略是这样工作的:选择其中一个可能的合并基准点并期望这是合并最好的结果。实际上这并没有听起来的那么糟糕。通常情况下用户修改不同部分的代码,在这种情况下,很多的合并冲突其实是多余和重复的。而使用resolve进行合并时,产生的冲突也较易于处理,真正会遗失代码的情况很少。
recursive
仅仅使用三路合并算法合并两个分支。和resolve不同的是,在交叉合并的情况时,这种合并方式是递归调用的,从共同祖先节点之后两个分支的不同节点开始递归调用三路合并算法进行合并,如果产生冲突,那么该文件不再继续合并,直接抛出冲突;其他未产生冲突的文件将一直执行到顶部节点。额外地,这种方式也能够检测并处理涉及修改文件名的操作。这是git合并和拉取代码的默认合并操作。
recursive合并策略有以下参数:
|参数|作用|
|—|—|
|ours|该参数将强迫冲突发生时,自动使用当前分支的版本。这种合并方式不会产生任何困扰情况,甚至git都不会去检查其他分支版本所包含的冲突内容这种方式会抛弃对方分支任何冲突内容|
|theirs|正好和ours相反。theirs和ours参数都适用于合并二进制文件冲突的情况|
|patience|在这种参数下,git merge-recursive花费一些额外的时间来避免错过合并一些不重要的行(如函数的括号)。如果当前分支和对方分支的版本分支分离非常大时,建议采用这种合并方式|
|diff-algorithm=[patience|minimal|histogram|myers]|告知git merge-recursive使用不同的比较算法。|
|ignore-space-change
ignore-all-space
ignore-space-at-eol|根据指定的参数来对待空格冲突:
如果对方的版本仅仅添加了空格的变化,那么冲突合并时采用我们自己的版本
如果我们的版本含有空格,但是对方的版本包含大量的变化,那么冲突合并时采用对方的版本
采用正常的处理过程|
|no-renames|该选项是subtree合并策略的高级形式,将会猜测两颗节点树在合并的过程中如何移动。不同的是,指定的路径将在合并开始时除去,以使得其他路径能够在寻找子树的时候进行匹配。(关于subtree合并策略详见下文)|
|octopus|这种合并方式用于两个以上的分支,但是在遇到冲突需要手动合并时会拒绝合并。这种合并方式更适合于将多个分支捆绑在一起的情况,也是多分支合并的默认合并策略|
|ours|这种方式可以合并任意数量的分支,但是节点树的合并结果总是当前分支所冲突的部分。这种方式能够在替代旧版本时具有很高的效率。请注意,这种方式和recursive策略下的ours参数是不同的|
|subtree|subtree是修改版的recursive策略。当合并树A和树B时,如果B是A的子树,B首先调整至匹配A的树结构,而不是读取相同的节点|
总结
在使用三路合并的策略时(指默认的recursive策略),如果一个文件(或一行代码)在当前分支和对方分支都产生变化,但是稍后又在其中一个分支回退,那么这种回退的变化将会在结果中体现。这一点可能会使一些人感到困惑。这是由于在合并的过程中,git仅仅关注共同祖先节点以及两个分支的HEAD节点,而不是两个分支的所有节点。因此,合并算法将会把被回退的部分认为成没有变化,这样,合并后的结果就会变为另一个分支中变化的部分。
示例
1 | # 1. 合并分支fixes和enhancements在当前分支的顶部,使它们合并: |
rebas及合并本地提交记录
当执行rebase操作时,git会从两个分支的共同祖先开始提取待变基分支上的修改,然后将待变基分支指向基分支的最新提交,最后将刚才提取的修改应用到基分支的最新提交的后面。
比如:
- master: A–>B–>M
- feature: A–>B–>C–>D
在feature分支上执行git rebase master时,git会从master和featuer的共同祖先B开始提取feature分支上的修改,也就是C和D两个提交,先提取到。然后将feature分支指向master分支的最新提交上,也就是M。最后把提取的C和D接到M后面,注意这里的接法,官方没说清楚,实际是会依次拿M和C、D内容分别比较,处理冲突后生成新的C’和D’。一定注意,这里新C’、D’和之前的C、D已经不一样了,是我们处理冲突后的新内容,feature指针自然最后也是指向D’
合并本地提交记录
我们通常会通过 git rebase -i 或git rebase -i HEAD~3命令,-i 参数表示交互(interactive),该命令会进入到一个交互界面中,其实就是 Vim 编辑器; HEAD~3 表示从当前 HEAD 往前 3 个 commit,即最近3次提交。
这个交互界面会首先列出给定之前(不包括,越下面越新)的所有 commit,每个 commit 前面有一个操作命令,默认是 pick。我们可以选择不同的 commit,并修改 commit 前面的命令,来对该 commit 执行不同的变更操作。
| 命令 | 目的 |
|---|---|
| p,pick | 不对该commit做任何处理 |
| r,reword | 保留该commit,但修改提交信息 |
| s,squash | 保留该commit,但会将当前commit与上一个合并 |
| f,fixup | 与squash相同,但不会保存commit信息 |
| x,exec | 执行其他shell命令 |
| d,drop | 删除该commit |
除此之外,还需要注意以下几点:
- 删除某个 commit 行,则该 commit 会丢失掉。
- 删除所有的 commit 行,则 rebase 会被终止掉。
- 可以对 commits 进行排序,git 会从上到下进行合并。
分支合并
使用git rebase合并分支会导致节点先后顺序乱,谨慎使用。
可用于拉取公共分支最新代码(git pull -r或git pull --rebase)。这样的好处:提交记录会比较简洁。但缺点:rebase以后我就不知道我的当前分支最早是从哪个分支拉出来的.
推送代码绝对不要使用rebase,一旦提交历史信息错乱,不好追溯。
中断与继续 abort与continue
1 | # 该命令仅仅在合并后导致冲突时才使用。git merge --abort将会抛弃合并过程并且尝试重建合并前的状态。但是,当合并开始时如果存在未commit的文件,git merge --abort在某些情况下将无法重现合并前的状态。(特别是这些未commit的文件在合并的过程中将会被修改时) |
标签tag
tag 就是对某次 commit 的一个标识,相当于起了一个别名。分为两种:
- 轻量标签:只是某个 commit 的引用,可以理解为是一个 commit 的别名
- 附注标签:是存储在git仓库中的一个完整对象,包含打标签者的名字、电子邮件地址、日期时间以及其他的标签信息。它是可以被校验的,可以使用 GNU Privacy Guard (GPG) 签名并验证。
本地标签
创建标签
1 | # 轻量标签 |
查看标签
1 | # 查看所有标签列表 |
删除标签
1 | $ git tag -d [标签名称] |
远程标签
推送标签到远程仓库
1 | # 将指定的标签上传到远程仓库 |
注:默认情况下,git push 命令并不会把标签推送到远程仓库中,必须手动地将 本地的标签 推送到远程仓库中。
删除远程标签
1 | $ git push origin :regs/tags/[标签名称] |
检出标签
检出标签的理解:是在这个标签的基础上进行其他的开发或操作。
检出标签的操作实质:是以标签指定的版本为基础版本,新建一个分支,继续其他的操作。
因此 ,就是新建分支的操作了。
1 | $ git checkout -b [分支名称] [标签名称] |
PR流程
1 |
|
工作应用
1 | 1. git stash保存未提交的代码,并恢复本地仓库到修改前状态 |
如何保持分支和上游分支(upstream)同步?
1 | 1. 查看git状态 |
经验
- 多提交,少推送。多人协作时,推送会频繁地带来合并冲突的问题,影响效率。因此,尽量多使用提交命令,减少合并的使用,这样会节省很多时间。
- 使用Git流(Git Flow)
- 使用分支,保持主分支的整洁。这是我强烈推荐的一点,在分支进行提交,然后切到主分支更新(git pull —rebase),再合并分支、推送。这样的流程会避免交叉合并的情况出现(不会出现共同祖先节点为多个的情况)。事实上,git合并操作让很多人感到不知所措的原因就是各种原因所产生的交叉合并问题,从而造成在合并的过程中丢失某些代码。保持主分支的整洁能够避免交叉合并的情况出现。
- 禁用fast-forward模式。在拉取代码的时候使用rebase参数(前提是保持主分支的整洁)、合并的时候使用—no-ff参数禁用fast-forward模式,这样做既能保证节点的清晰,又避免了交叉合并的情况出现。
问题
push:HTTP 413 curl 22 The requested URL returned error: 413 Request Entity Too Large
使用ssh提交替换掉HTTP,如下:
1 | $ git remote set-url origin git@github.com:GitRepoName.git |
不同项目的合并
1 | # 现在有两个仓库 [leader/kkt](https://www.leader755.com) (主仓库) 和 [leader/kkt-next](https://www.leader7555.com)(子仓库) |
参考文章
- Git 最佳实践 入门
- Git 工作流程
- Git 使用规范流程
- git merge详解
- 等(可能还有一些文章没有回忆起来,也没有再找到,抱歉)

